
Introduction
BGP is one of the most used protocols: it can be found in campus, datacenters and above all in the ISP realm. It is everywhere. You will find it soon or later.
Even though it is extremely popular, many people feel uncomfortable when talking or dealing with BGP. That’s normal, as it is much more complex than the average protocol.
In a series of posts, we are going to make it easier to understand and get you more comfortable with it.
What’s BGP?
If we were in a TV show and I’m asked what’s coming to your mind when you think of BGP:
- Very scalable (can growth with ease)
- Super flexible and good for traffic engineering
- Open standard
- Widely used, it is the soul of the Internet
- Control plane slow to converge (data plane can be very fast actually)
BGP is the Internet basically, it is what is moving all the routes through the world. It’s the only protocol that can handle millions of prefixes without sweating too much.
Right now, the global BGP table it is getting close to 1 million IPv4 prefixes and growing; yet no other protocol can hold that many routes without going insane(crashing).
Why IGPs can’t hold full Internet routes?
For starters, IGP as EIGRP or OSPF they need to know a lot of information to work: links, neighbors, which neighbor is connected to which other neighbor, prefixes…Furthermore for link-state protocols as OSPF or IS-IS they need to keep even more information, as a full view of an area (topology information, who is connected to who) and also for instance they require the database to be refreshed at least 1h per hour.
Additionally, for link-state protocol we have also the problem that every area must keep the same exact information and all must be synchronized periodically. For EIGRP we would have to run DUAL algorithm is there is any change in the network as another example of the IGP complexity.
That’s a lot of information to keep, maintain and sent to all your neighbors. Even the OSPF messages LSA or EIGRP updates they have a limit on how big it can be, there is a limit on the prefixes that can be exchanged.
Now in contrast, BGP do not have to deal with so many problems as IGP needs to deal with. BGP in essence only cares about who is my next hop and how I can reach it; that’s it.
The fact that BGP also uses TCP as it’s session mechanism helps to exchange bigger size routes and more prefixes with error detection.
Wait, it doesn’t look like a protocol
It’s true that many people argue that BGP it is not a protocol per se, it is more like an application. And I would agree also.
BGP only cares about who is my next hop and how to reach it, it has no visibility underneath of the topology.
Normally BGP cannot route alone, it relies frequently in IGP doing the routing decision dirty work. This work can be finding the best path or map the full network topology.
In fact, BGP do not care about links delay or bandwidth; only routes according to prefixes(routes) attributes. Doing policies and traffic engineering is way easier with BGP.
ASN: Autonomous System Number, key idea
We can define an autonomous system as a group of routers under the same management domain, for example a company.
If you have 100 routers under the same ASN, other external BGP neighbors (outside of your ASN) will see your ASN as a single hop. BGP only see in ASN hops, not internal routers of that ASN hops.
Routers inside your own ASN are considered internal BGP peers, or iBGP peers.
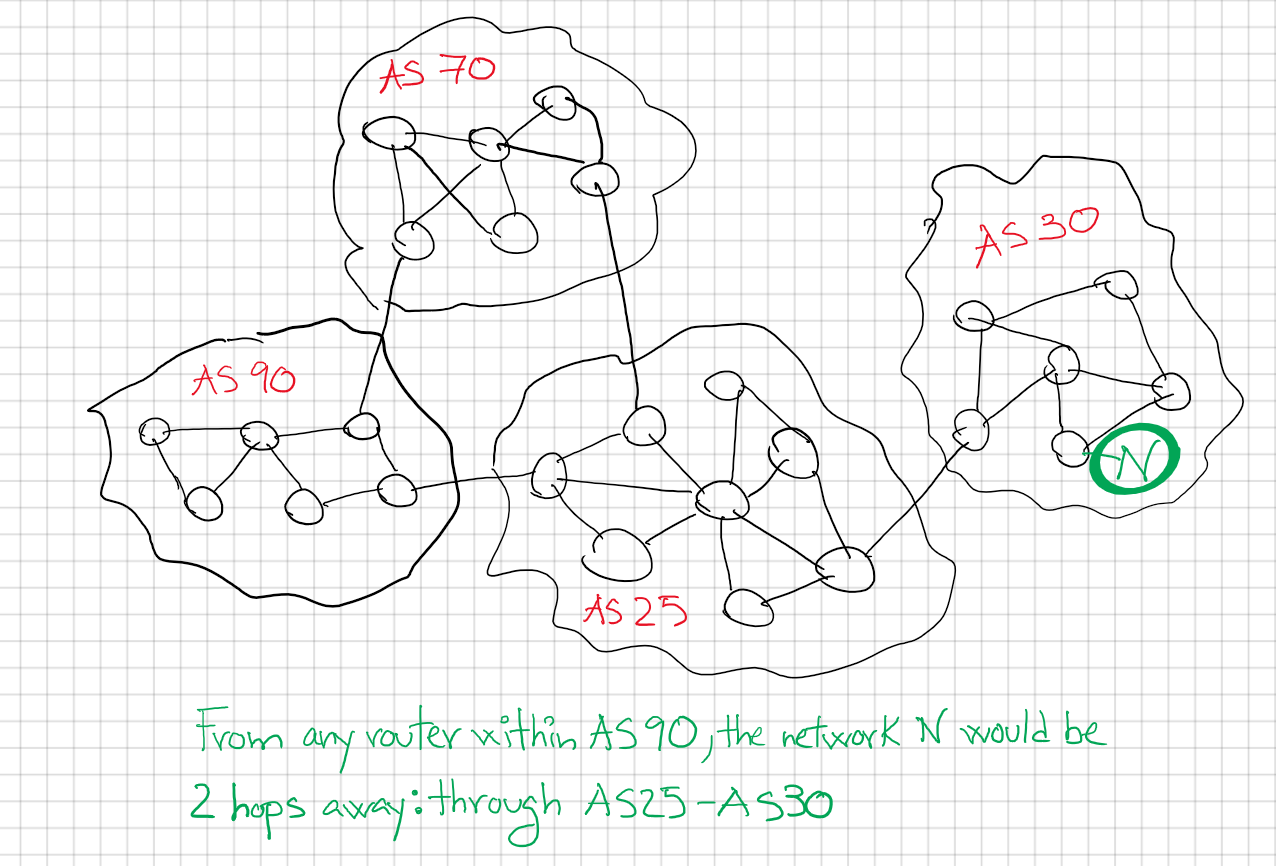
From AS 90, the path to network N would be passing through AS25 and AS30, this is called the AS_PATH. When route N is advertised from AS30 to AS25 it will append its own ASN into the prefix. Similarly, when the same route will be advertised from AS25 to AS90 it will append AS25 into the prefix.
You would see the route as “to reach N go first through AS 25 and later through AS 30.”
The AS_PATH is a mandatory attribute, it means it will be always present in each prefix route. AS_PATH give us information about which ASN the route passed through and also it is used as a loop prevention mechanism.
If we see our own ASN in the AS_PATH we will reject that route. Imagine if AS 90 announced a route to AS 70, then AS 70 will pass it onto AS 25 and AS 25 will send it back to AS 90. AS 90 would reject that update as they will see their own ASN into the update.
Also, AS_PATH could be used as a hop count to decide which path it is better (shorter) if we receive the same prefix from different places. Shorter ASN count would win. But not always as AS_PATH it is just one way to decide which route is better than another. There are other ways and a full hierarchy about which path would be more preferred than another.
Equally important is to know about public and private ASN. Originally, we used to have 65536 (16 bits) of possible ASN numbers.
As with IPv4, the shortage of ASN number appeared quite early. Also, you have to take into account that 1023 were reserved for Private usage (64512-65534).
Now we have the possibility to use 32 bits or 4 bytes for ASN; so not to worry much for now as we have over 4 billion numbers. Private numbers are about 94 million with 4 byte ASNs.
BGP: External vs Internal
An external or internal neighbor it is going to be determined in the exact moment that we configure the neighbor command.
An external (aka eBGP) will have different Autonomous System Number (ASN). An internal(aka iBGP), however will have the same ASN as ours.
There are different rules and caveats with each type of neighbor.
eBGP notes:
- AD is 20 (vs 200 for iBGP)
- AS_PATH as loop prevention.
- TTL=1, if you want to have a far away neighbor you have to modify this.
- Router advertising a prefix will put itself as a next hop.
iBGP notes:
- AD is 200
- Split horizon as loop prevention. Routes learnt from an iBGP peer won’t be sent to another peer.
- TTL=255, you can have far a way iBGP neighbor without any extra commands.
- Router advertising a prefix will not change the next hop, will keep it as it is.
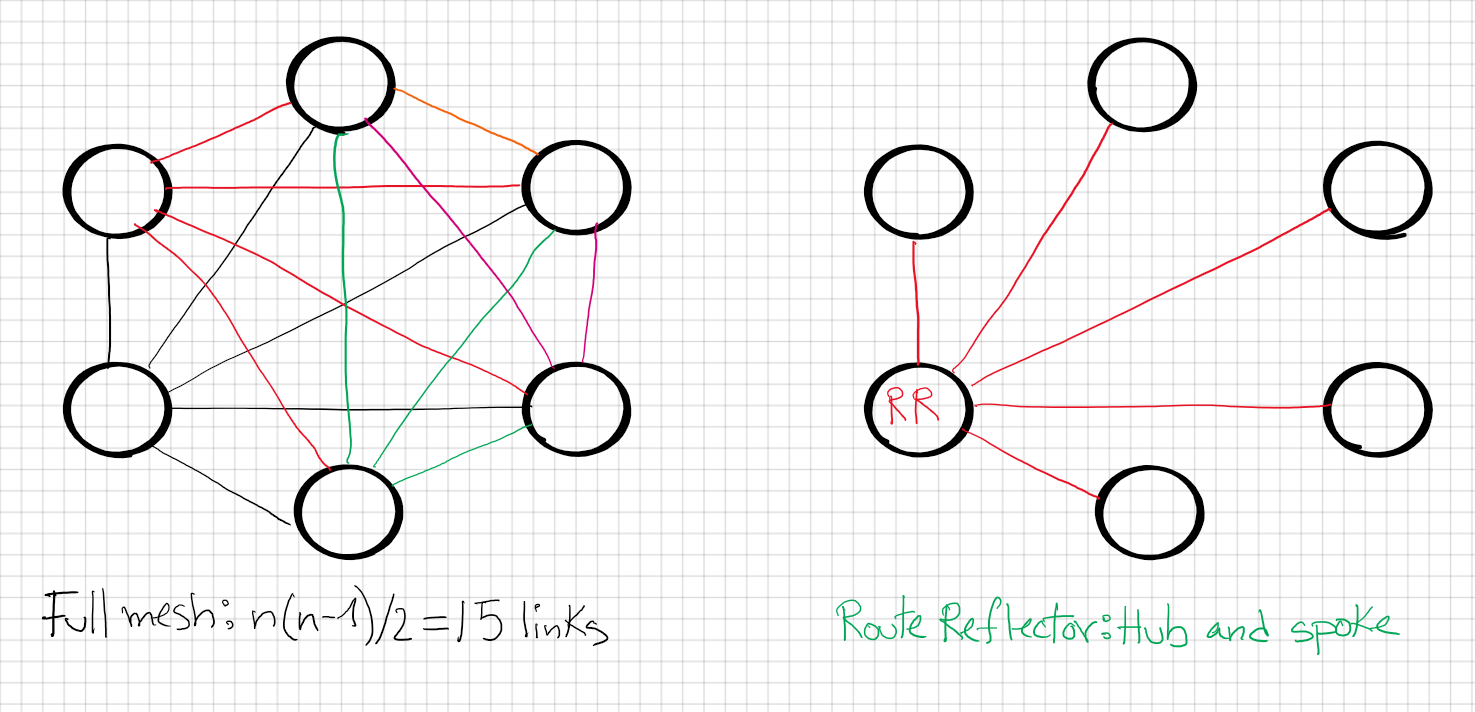
- Full mesh required. Scaling mechanisms such as Route reflector or Confederations are an alternative.
Indeed, the biggest problem with iBGP(internal) is that we have to deal with split horizon safety rules because we cannot use AS_PATH as a loop prevention.
Dealing with split horizon implies that we would have to do a full mesh(everybody connects with everybody) which require to use the well-known formula n(n-1)/2
10 routers imply, 10(10-1)/2= 45 total connections. Also, that do not scale good at all. Imagine maintaining that quantity of links. No, thank you.
Fortunately, we have two way out of this problem:
- Route reflectors
- Confederations.
Those solutions will help us with scaling of the network.
Route reflector idea is as such:
On the other hand, Confederations are a way to divide an ASN into smaller sub autonomous systems, for instance:
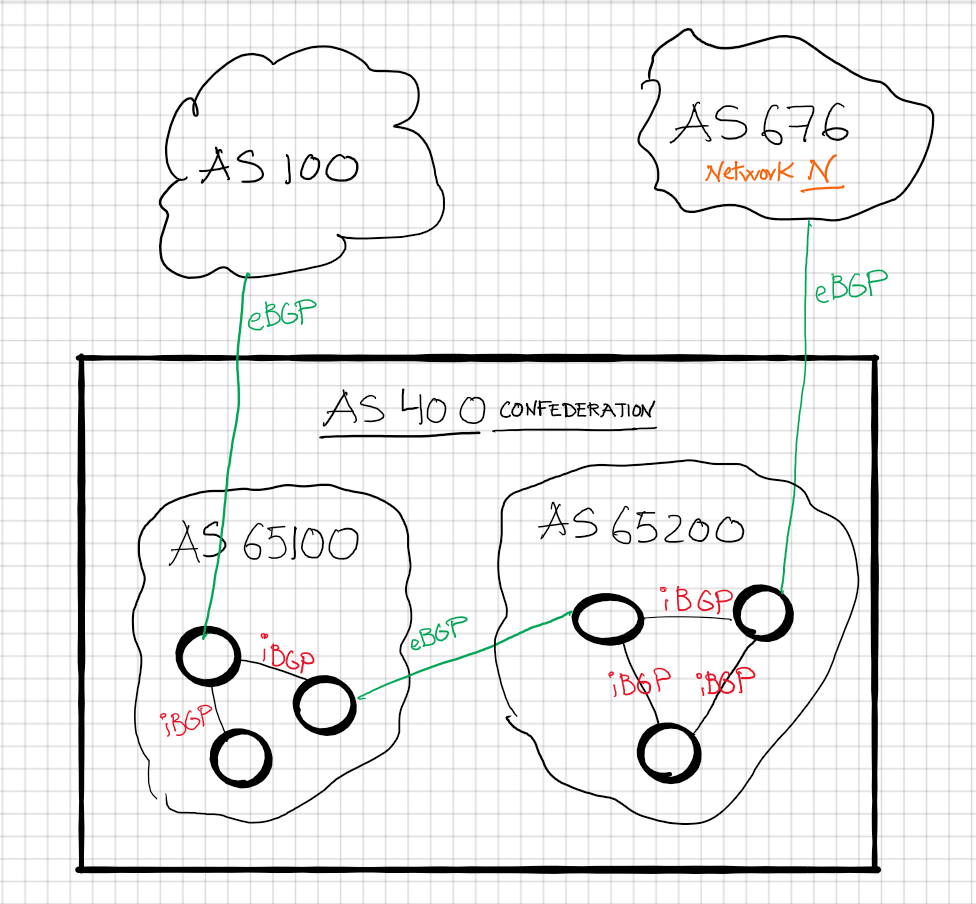
Network N being received in the AS100, would look as: AS400-AS676 as we won’t see internal sub-confederation path
Home and multi-homed topologies
Maybe you have heard in your company or while ready a book something about “home” regarding BGP.
Basically, we have 4 options for our company “C”:
Single homed: One link(single) to One ISP(homed)
Dual homed: Two links(dual) to One ISP(homed)
Single multi-homed: One link(single) to two ISP(dual-homed)
Dual multi-homed: Two links(dual) to two ISP(dual-homed)
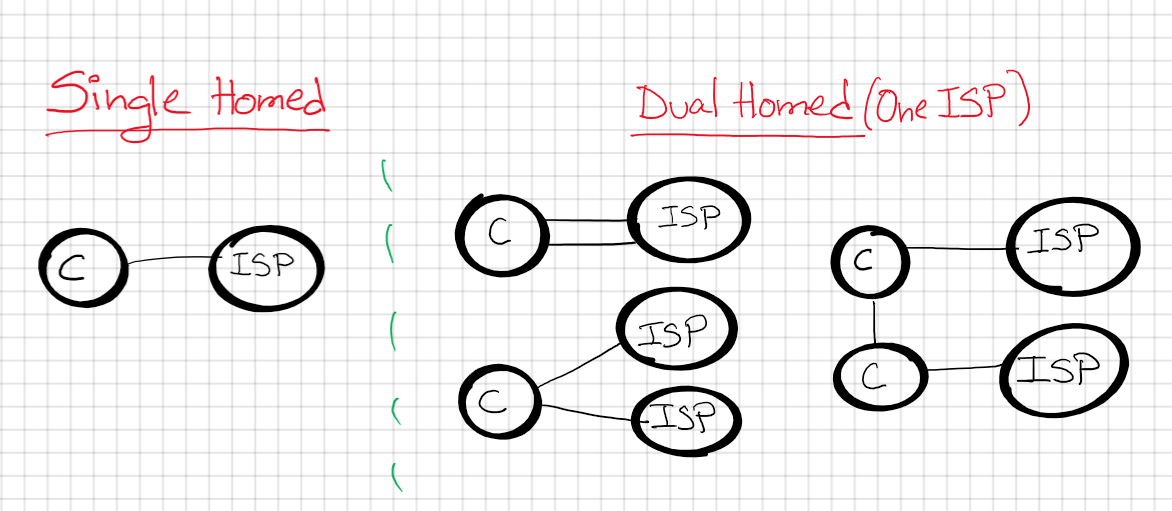
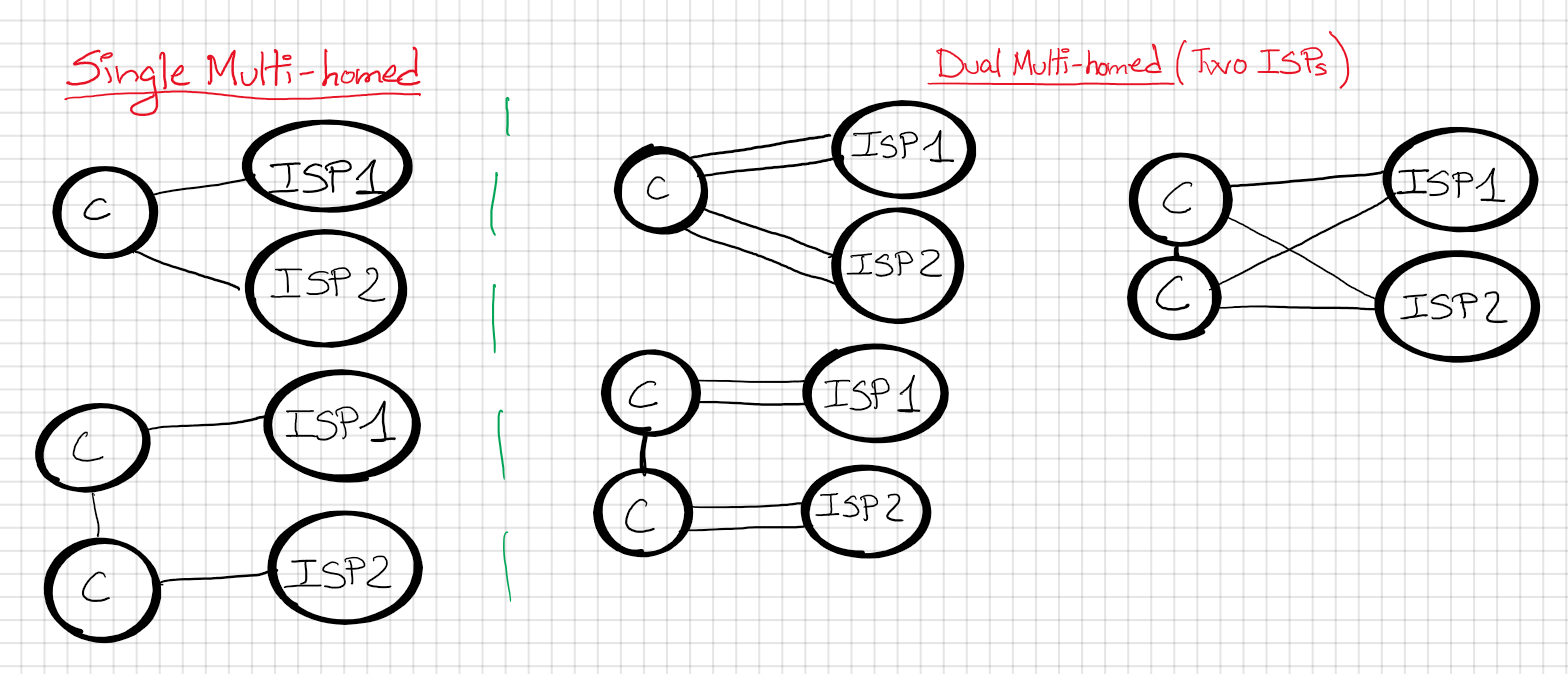
Big summary:
Single vs Dual: How many links? 1 or 2
Homed vs Multi-homed: How many ISPs? 1 or 2.
Conclusion
BGP is carrying over its shoulders the weight of the Internet, I hope that now you became a little more familiar with it.
We will continue over the next few post talking about BGP!
Check my other BGP post about filtering here.
Any thoughts?




Recent Comments